

ה”פוליטי-מטר” העברי הראשון פותר את תעלומת גנץ; לו היו בחירות ישירות מי היה נבחר לראשות הממשלה; סיוע לקמפיינרים ומצביעים מתלבטים; האם אפשר להחליף סקרים בכלים אוטומטיים לעיבוד שפה טבעית. כל זאת ועוד עם קצת דמיון (מודרך)
אז מה היה לנו שם?
בפוסט הקודם, דיברנו על “קסם” אלגוריתמי שמאפשר ללמוד בצורה אוטומטית מאוסף גדול של טקסטים (“קורפוס”) וללא שימוש במקורות מידע חיצוניים כגון וויקיפדיה ייצוג מספרי לכל מילה. ליתר דיוק ייצוג של כל מילה כוקטור של מספרים המכונה embedding. גם ראינו שהייצוג הנ”ל חושף מידע סמנטי אודות המשמעות של המילה כך שלמשל ניתן לפתור אנלוגיות פוליטיות בסגנון של “נתניהו לקואליציה כמו מי לאופוזיציה?“.
יכול להיות שיש כאלו שיופתעו מהמשפט הבא (אז אולי כדאי לקרוא אותו בישיבה) אבל הייצוג הנ”ל לא ממש נועד לפתור אנלוגיות פוליטיות. למעשה הוא נועד כדי להמיר קלט טקסטואלי לפורמט מספרי שמהווה קלט נוח יותר להרבה אלגוריתמים בעולם של לימוד מכונה (machine learning) באופן כללי, ועיבוד שפה טבעית (natural language processing) באופן ספציפי. אבל כפי שנהוג לומר (וסליחה על הנדושות) “הי, אם כבר למדנו ייצוג כזה אפשר לעשות איתו לא מעט דברים נחמדים“.
עוד תזכורת קטנה וחשובה – במקרה שלנו, את הייצוג למדנו על קורפוס פוליטי אשר מבוסס על טוויטים של ח”כים, מפלגות, עיתונים, ערוצי חדשות, עיתונאים, משרדים ממשלתיים ועוד מקורות. כשנותנים למחשב ללמוד ייצוג על קורפוסים שונים הוא לומד דברים קצת אחרים על העולם. דמיינו מעין רפונזל מודרנית שמסוגרת במגדל ויכולה ללמוד על העולם רק משבועונים שמקבלת משום מה מהאם החורגת שלה. ברור שאם יש לה מנוי לנשיונל ג’יאוגרפיק היא תבין את העולם אחרת מאשר אם היא מנויה רק לישראל היום, למרות שיש לא מעט מילים חופפות בין שני הקורפוסים הללו.
ימין ושמאל רק חול וחול
מקובל להגיד שהחלוקה לימין ושמאל בישראל שונה מזו שבשאר המדינות. מומחים עשויים להזכיר מאפיינים לאומיים, כלכליים, פופוליסטיים, דתיים. אני לא מומחה במדעי המדינה, אבל לשמחתי זה לא בלוג פוליטי במובן הצר של המילה ולכן אין צורך להיכנס להגדרות מדויקות. יותר מזה, לא ממש משנה ההגדרה המדויקת של ימין לעומת שמאל כי בסופו של דבר השאלה היא מהי התפיסה של האדם ברחוב לגבי ההבדל בין ימין לשמאל ובמקרה שלנו איך המושגים האנושיים “ימין” ו-“שמאל” משתקפים בקורפוס.
בהינתן העמימות היחסית של המושגים ימין ושמאל, לא פעם ובפרט לקראת מערכת בחירות, השיח הבין-מפלגתי בישראל הופך למאבק תודעתי. כשנלחמים על מנדטים בתוך אותו הגוש, כל מפלגה מנסה להצטייר טהורה יותר. הימניים יאשימו את מפלגת האחות הימנית בשמאלנות, השמאלנים את אחיהם השמאלניים בימניות ואלו שבמרכז (ככל שיש מרכז) יקראו לכל השאר קיצוניים. לי באופן אישי זה קצת מזכיר את המערכון של מונטי פייטון עם people’s front of Judea.
כחלק מהעניין, התקשורת מתחבטת שבועות ארוכים איפה בעצם בני גנץ ממוקם במפה הפוליטית, וכשאין תשובות ברורות מתחילים לפשפש בעברו ולחפש התבטאויות מרמזות שלו או של משפחתו וחבריו. אז הנה פיתרון שעוד לא חשבו עליו – “הפוליטי-מטר העברי הראשון” – נשתמש בייצוג הוקטורי שלמדנו מהקורפוס ונמדוד האם המשמעות הסמנטית של “גנץ” כפי שמיוצגת ע”י וקטור קרובה יותר לייצוג הוקטורי של המושג “ימין” או לזה של המושג “שמאל“. למעשה, אנחנו נעשה יותר מזה, כדי להעריך עד כמה השיטה הזאת עובדת אנחנו ניישם אותה על כל ראשי המפלגות המובילות (ומכאן שלוחה התנצלות חמה לאיימן עודה אבל אני מתמקד בטוויטים בעברית ולכן הוא לא נכלל בבדיקה, חוץ מזה, הוא הודיע על פרישה ועוד לא נבחר לו מחליף).
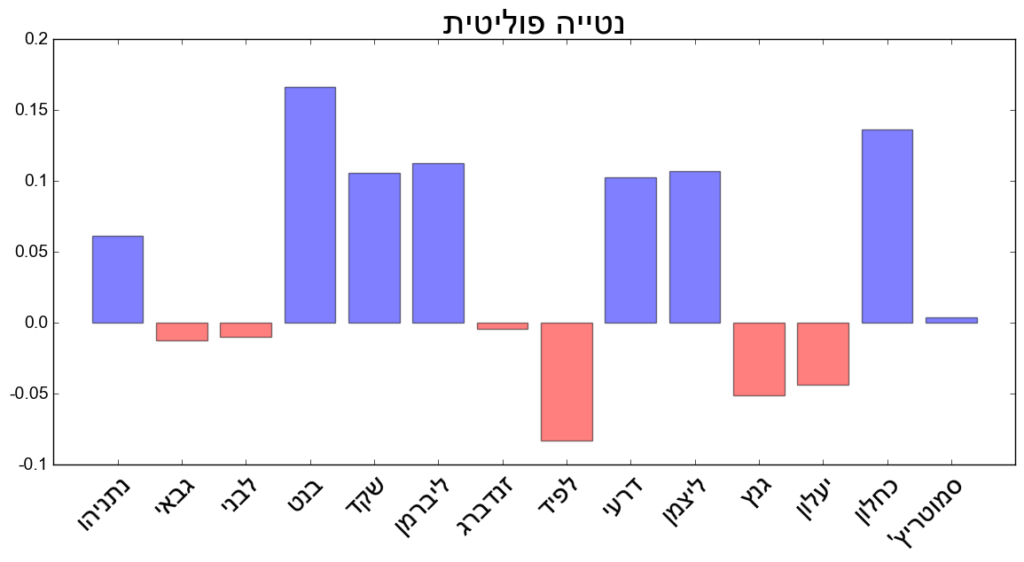
נטייה פוליטית של מנהיגי המפלגות כפי שנמצאה באופן אוטומטי ע”י דמיון סמנטי יחסי למושגים “ימין” ו-“שמאל”.
בגרף למעלה מוצג הפער היחסי בין הדימיון או הקירבה שבין הייצוג הוקטורי של כל פוליטיקאי למושג “ימין“, לבין אותה קירבה בין הפוליטיקאי למושג ” שמאל“. פער חיובי מבטא קירבה גדולה יותר למושג “ימין” ומסומן בכחול, ופער שלילי מבטא קירבה גדולה יותר לשמאל ומסומן באדום.
שוב, באופן מאוד מרשים ואולי קצת מפתיע, אפשר לראות בגרף שלפחות בחלוקה הגסה של ימין/שמאל השיטה הנ”ל מצליחה לסווג את הפוליטיקאים המוכרים בצורה נכונה ולכן אפשר להעריך שגם גנץ מסווג נכון והוא שייך לאגף השמאלי של המפה הפוליטית כפי שאכן מאושש ע”י הסקר האמיתי להלן. צריך לציין שגודל המשרעת (אמפליטודה) של כל פוליטיקאי מושפע לא רק מרמת ה-“קיצוניות” שלו אלא גם מטיב הייצוג שלו בטוויטר ולכן למשל סמוטריץ’ שנכנס רק בימים האחרונים להנהגת מפלגת תקומה, נראה פחות ימני מנתניהו, למרות שסביר שהמצב האמיתי הפוך. מעבר לכך, חשוב להדגיש גם שמקורות שונים מייצגים פוליטיקאים באור שונה ולכן הימניות של מיודענו סמוטריץ’ פחות מודגשת כי הוא מכוסה יותר ע”י מקורות חדשות מהמגזר הימני ופחות מהמרכז וביחס למקורות חדשות אלו, סמוטריץ’ לא ימני במיוחד. בהמשך הסידרה מתוכנן פוסט שמשווה בין עיתונים, ערוצי חדשות וכו’ כדי לבחון האם יש משמעות לדיווח אובייקטיבי או שהכל תלוי בנטייה הפוליטית של המוציא לאור.

סקר אמיתי מתאריך 17.1.19 לגבי שיוכו הפוליטי של בני גנץ. רוב הציבור מעריך כי גנץ ממוקם בצד השמאלי של המפה הפוליטית כפי שעולה גם מהניתוח הסמנטי על טוויטר.
מבחן מנהיגות
מעבר לבחינת אחוזי התמיכה המפלגתית, שאלה שמופיעה בחלק מהסקרים במערכת הבחירות היא “מי הכי מתאים בעיניך להנהיג את המדינה / להיות ראש ממשלה?“. אמנם שאלה קצת תיאורטית כי אין כרגע בחירה ישירה לראשות הממשלה וכל מועמד שייבחר בסופו של דבר יגיע עם שלל חבריו הססגוניים מהשורות האחוריות במפלגה, ועדיין שאלה לגיטימית.
גם על שאלת המנהיג המועדף אפשר לענות ע”י מדידת הקירבה בין הייצוג סמנטי של כל פוליטיקאי לייצוג של המילה “מנהיג” כפי שהם נלמדים מקורפוס הטוויטים. בגרף הבא מוצגים הפוליטיקיאים המובילים ברמת הדמיון לייצוג הסמנטי של המושג “מנהיג“.
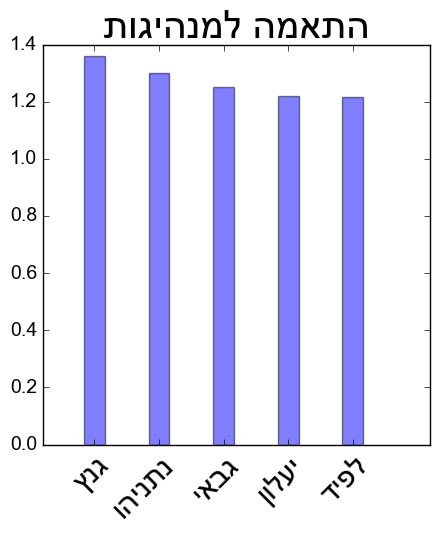
פוליטיקאים בעלי דמיון גבוה לייצוג הסמנטי של המילה “מנהיג”
זה הזמן להסתייג ולהגיד שכמו סקרים שנכונים (לכל היותר) רק לרגע שבו נעשו, גם שימוש בדמיון סמנטי בכדי לאבחן מי מזוהה כיותר מתאים להנהגה מוגבל ברמת הדיוק ולו בגלל ההסתמכות על אוכלוסיה לא מייצגת של משתמשים בטוויטר. מעבר לזה, גם בדמיון סמנטי כמו בסקרים לא כדאי להסתמך על הפער המדויק בין המקומות הראשונים אלא יותר על התמונה הגדולה – למשל מי בקבוצת המובילים, האם יש פער בין המקומות הראשונים או שהם צמודים יחסית. במקרה שלנו, נחמד לראות שנכון לשעת ניתוח הקורפוס, התוצאות משקפות מאבק צמוד בין גנץ לנתניהו על הדמות המועדפת להנהגה כפי שגם עולה בסקר להלן.

סקר אמיתי מתאריך 17.1.19 לגבי ראש הממשלה המועדף על הציבור
מת מתל מתלב מתלבט (במי לבחור)
עוד שימוש יפה שאפשר לעשות בדמיון סמנטי הוא למדוד את הקירבה בין המועמדים והמפלגות השונות כפי שעולה מהדמיון בייצוג הוקטורי שלהם. למה זה טוב? נניח שאתם קמפיינרים של מפלגה/מועמד ורוצים לדעת איך להתקדם, שאלה בסיסית היא מי המתחרים שצריך לבדל את עצמך מהם ע”י הדגשת תכונות/מצע כאלו ואחרים. באותה מידה, אם אתם שוקלים להצביע למועמד מסוים, מציאת מועמדים שדומים לו תחדד אצלכם את הפרמטרים על פיהם אתם מצביעים ותעזור לכם להצביע נכון יותר.
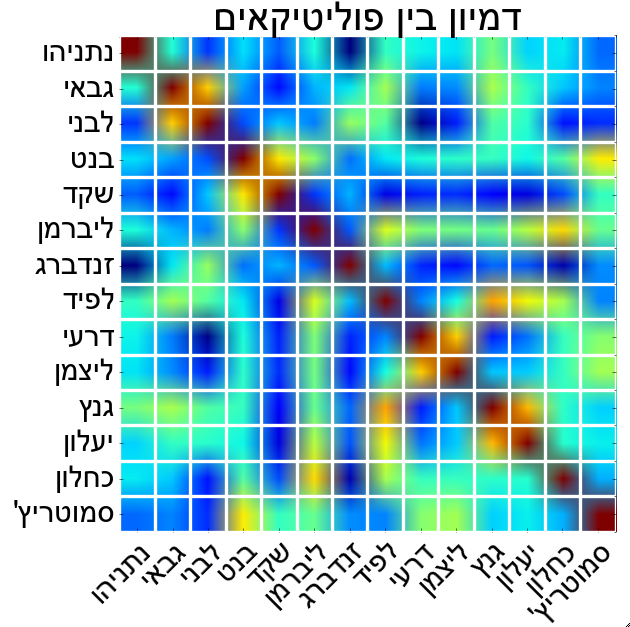
“מפת חום” אשר מתארת דמיון בין פוליטיקאים. ככל שהפוליטיקאים בטור ושורה מסוימים קרובים יותר זה לזה, צבע המשבצת בה הטור והשורה מצטלבים יתקרב לאדום. לעומת זאת כחול מבטא מרחק גדול בין הפוליטיקאים.
במפת החום (heat map) שלעיל, הקירבה בין הפוליטיקאים שבכל שורה ועמודה מתבטאת בצבע של המשבצת בה העמודה והשורה מצטלבות – צבע כחול כהה מבטא חוסר דמיון מובהק וככל שהדמיון גדל והפוליטיקאים קרובים יותר, צבע המשבצת “יתחמם” עד שיגיע לאדום. האלכסון הראשי ממנו אפשר להתעלם הוא כמובן אדום כיוון שמתאר קירבה מושלמת בין כל פוליטיקאי לעצמו. אפשר לראות למשל שהפוליטיקאי המאוים ביותר ע”י כניסתו של גנץ הוא יאיר לפיד. באופן דומה אפשר לראות שליצמן ודרעי מאוד קרובים, דבר שמסביר את המגעים לאיחוד אפשרי בין יהדות התורה וש”ס.
האם כלים מעין אלו של מדע נתונים יכולים להחליף סקרים?
לא.
ובכל זאת?
כן, לפחות בצורה חלקית כפי שראינו. מה שבטוח הוא שניתוח אוטומטי פאסיבי שכזה (ללא פנייה ישירה למשתמשים) ניתן לעשות בכל רגע נתון בעלות אפסית ובניגוד לסקר בניתוח שכזה ניתן “לשאול” כמה שאלות שרוצים. אבל מצד שני יש גם פערים שדורשים התייחסות – למשל, נדרש כיסוי טוב ומדוייק יותר של משתמשים בטוויטר, פילוח דמוגרפי וגיאוגרפי, זיהוי סנטימנט, איתור של משתמשים מזויפים (“בוטים”), התייחסות לאמינות ואובייקטיביות של הצייצן, מידת השפעה של הצייצן על משתמשים אחרים ועוד. בפוסטים הבאים בסדרה אתאר כיצד ניתן להתמודד עם פערים אלו.
הערות והרחבות
- שוב אני עושה שימוש בחבילת הפייטון gensim לטובת עבודה עם ייצוגים וקטוריים.
- כדי לשמור על מדידה אחידה ככל האפשר הייצוג הוקטורי של כל פוליטיקאי הוא מעין ממוצע ממושקל על ייצוגים שונים אפשריים שלו הכוללים את שם חשבון הטוויטר שלו והטיות שונות על שם המשפחה של אותו הפוליטיקאי. למשל, במקרה של נפתלי בנט יש פה ממוצע בין הייצוגים של “naftalibennett@”, “בנט”, “ובנט”, “שבנט”, וכו’. המשקל היחסי של כל ייצוג נגזר מהשכיחות היחסית של הביטוי בקורפוס לעומת ביטויים אחרים. למשל, “בנט” יותר שכיח בקורפוס מ-“שבנט” ולכן משקל הוקטור של “בנט” בממוצע המשוקלל יהיה גבוה יותר מהמשקל של הוקטור המתאים ל-“שבנט”. טכנית הממוצע הנ”ל מחושב ע”י numpy.average
- הגרפים נוצרו ע”י חבילת פייטון מומלצת בשם matplotlib. ישנן עוד חבילות מומלצות כגון plotly שיכולות גם להציג גרפיקה דינמית כפי שנדגים בפוסט הבא.
- בכדי לייצר מטריצת דמיון כמו זו של ה-heatmap ניתן להשתמש עקרונית ב-similarity_matrix של gensim. בפועל לא השתמשתי בה כיוון שרציתי למצוא דמיון בין וקטורים ממושקלים כפי שתואר לעיל ולכן חישבתי ישירות את המטריצה


